Speeding up “suggest” with python-Levenshtein¶
sphobjinv uses fuzzywuzzy for fuzzy-match searching of object
names/domains/roles as part of the
Inventory.suggest() functionality,
also implemented as the CLI suggest subcommand.
By default, fuzzywuzzy uses difflib.SequenceMatcher
from the Python standard library for its fuzzy searching.
However, it also can use python-Levenshtein,
a Python C extension providing
similar functionality. Thus, sphobjinv has been implemented with
python-Levenshtein as an optional dependency: it will be
used if it is available.
Installation¶
On Linux and MacOS, installing sphobjinv with the speedup extra
should work properly to install python-Levenshtein
in the vast majority of cases:
$ pip install sphobjinv[speedup]
If you need to work with a version of sphobjinv prior to v2.1,
the speedup extra is not available and direct installation
is required:
$ pip install sphobjinv==2.0.1 python-Levenshtein
On Windows, as of this writing no binary wheel is available on PyPI. So, the easiest way to install is to download a wheel from Christoph Gohlke’s repository and run pip install C:\path\to\wheel. Just make sure to match Python version and CPU type (win32 vs win_amd64) when you download.
Performance Benchmark¶
The chart below presents one dataset illustrating the performance enhancement
that can be obtained by installing python-Levenshtein.
The timings plotted here are from execution of
timeit.repeat() in the
Python standard library around a
suggest() call,
searching for the term “function”, for a number of
objects.inv files from different projects (see
here).
The timings were collected using the following code:
import sphobjinv as soi
durations = {}
obj_counts = {}
for fn in os.listdir():
if fn.endswith('.inv'):
inv = soi.Inventory(fn)
# Execute the 'suggest' operation 20 times for each file
timings = timeit.repeat("inv.suggest('function')", repeat=20, number=1, globals=globals())
# Store the average timing for each file
durations.update({fn: sum(timings) / len(timings)})
# Store the number of objects
obj_counts.update({fn: inv.count})
As can be seen, the fifty-two objects.inv files in this dataset contain widely varying numbers of objects \(n\):
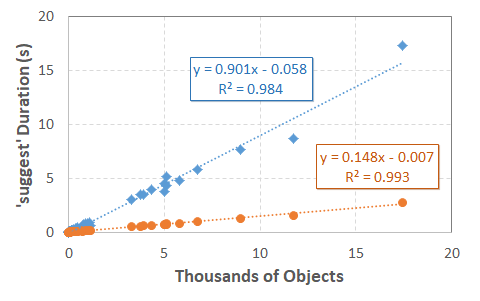
Unsurprisingly, larger inventories require more time to search.
Also relatively unsurprisingly, the time required appears to be
roughly \(O(n)\), since the fuzzy search must be performed once on the
as_rst representation of each object.
For this specific search, using python-Levenshtein instead of
difflib decreases the time required from 0.90 seconds per thousand objects
down to 0.15 seconds per thousand objects,
representing a performance improvement of almost exactly six-fold.
Other searches will likely exhibit somewhat better or worse
improvement from the use of python-Levenshtein,
depending on the average length of the reST-like representations
of the objects in an objects.inv
and the length of the search term.
Variations in Matching Behavior¶
Note that the matching scores calculated by
difflib and python-Levenshtein can often
differ appreciably. (This is illustrated in
issue #128
of the fuzzywuzzy GitHub repo.)
This difference in behavior doesn’t have much practical significance,
save for the potential of causing some confusion between users with/without
python-Levenshtein installed.
As an example, the following shows an excerpt of the results of a representative
CLI suggest call without
python-Levenshtein:
$ sphobjinv suggest objects_scipy.inv surface -asit 40
Name Score Index
------------------------------------------------------ ------- -------
:py:function:`scipy.misc.face` 64 1018
:py:function:`scipy.misc.source` 64 1032
:std:doc:`generated/scipy.misc.face` 64 4042
:std:doc:`generated/scipy.misc.source` 64 4056
:py:data:`scipy.stats.rice` 56 2688
:std:label:`continuous-rice` 56 2896
:py:method:`scipy.integrate.complex_ode.successful` 51 156
:py:method:`scipy.integrate.ode.successful` 51 171
:py:function:`scipy.linalg.lu_factor` 51 967
... more with score 51 ...
:py:attribute:`scipy.LowLevelCallable.signature` 50 5
:py:function:`scipy.constants.convert_temperature` 50 53
:py:function:`scipy.integrate.quadrature` 50 176
... more with score 50 and below ...
This is a similar excerpt with python-Levenshtein:
Name Score Index
------------------------------------------------------ ------- -------
:py:function:`scipy.misc.face` 64 1018
:py:function:`scipy.misc.source` 64 1032
:std:doc:`generated/scipy.misc.face` 64 4042
:std:doc:`generated/scipy.misc.source` 64 4056
:py:method:`scipy.integrate.ode.successful` 51 171
:py:function:`scipy.linalg.lu_factor` 51 967
:py:function:`scipy.linalg.subspace_angles` 51 1003
... more with score 51 ...
:py:function:`scipy.cluster.hierarchy.fcluster` 49 23
:py:function:`scipy.cluster.hierarchy.fclusterdata` 49 24
:py:method:`scipy.integrate.complex_ode.successful` 49 156
... more with score 49 and below ...